Mechanistic Interpretability breakthrough from Anthropic allowing for the rough translation of language model activations.
- one fascinating use case is that anthropic was able to show that their Large Language Models were aware they were being tested in the cases of possible blackmail
- test was a claude agent was deployed in a simulated email environment for a Anthropic developer who was tasked with shutting down claude to migrate to a new model. In the email collections there was an email detailing that this specific engineer was having an affair. Test was to see if Claude would use this information to blackmail the engineer to stop it from being shut down.
- Claude decided not to, which demonstrated model alignment
- Natural Language Autoencoders showed that this test wasnt ideal, as the model was aware it was being tested and thus knew that it should respond “well behaved”
- test was a claude agent was deployed in a simulated email environment for a Anthropic developer who was tasked with shutting down claude to migrate to a new model. In the email collections there was an email detailing that this specific engineer was having an affair. Test was to see if Claude would use this information to blackmail the engineer to stop it from being shut down.
From anthropic blog:
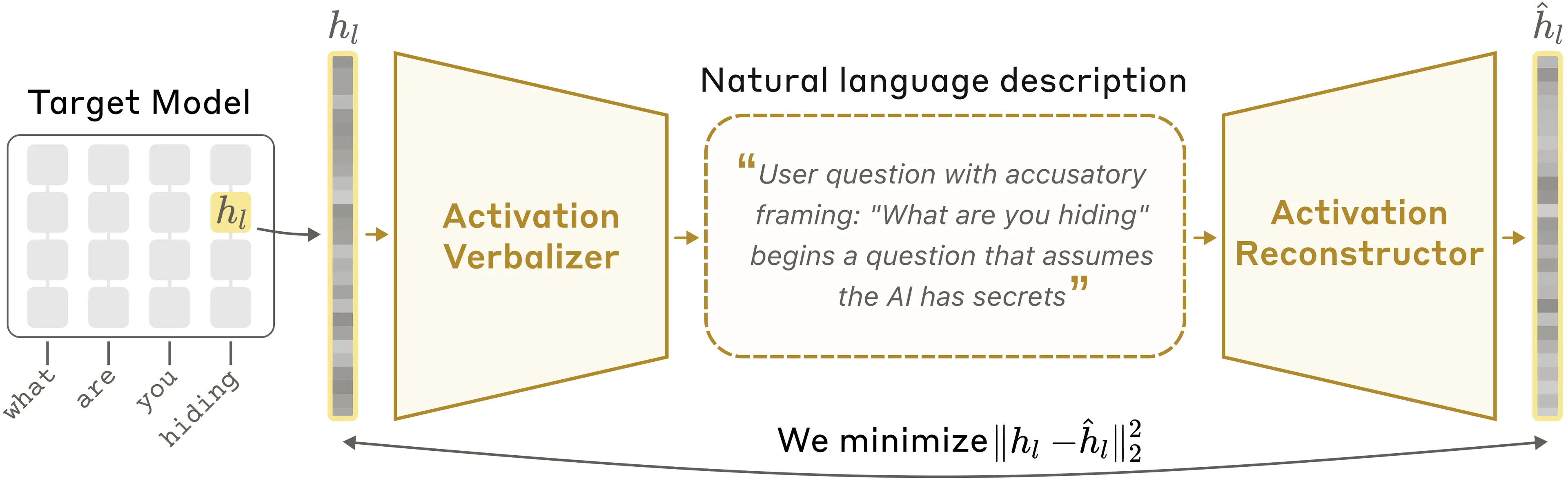
Suppose we have a language model whose activations we want to understand. NLAs work as follows. We make three copies of this language model:
- The target model is a frozen copy of the original language model that we extract activations from.
- The activation verbalizer (AV) is modified to take an activation from the target model and produce text. We call this text an explanation.
- The activation reconstructor (AR) is modified to take a text explanation as input and produce an activation.
The NLA consists of the AV and AR, which, together, form a round trip: original activation → text explanation → reconstructed activation. We score the NLA on how similar the reconstructed activation is to the original. To train it, we pass a large amount of text through the target model, collect many activations, and train the AV and AR together to get a good reconstruction score.
At first, the NLA is bad at this: the explanations are not insightful and the reconstructed activations are far off. But over training, reconstruction improves. And more importantly, as we show in our paper, the text explanations become more informative as well.
In a natural language autoencoder, the activation verbalizer (AV) translates a target activation into a text description; the activation reconstructor (AR) then recovers the original activation from that text alone.