The architecture that kicked it all off.
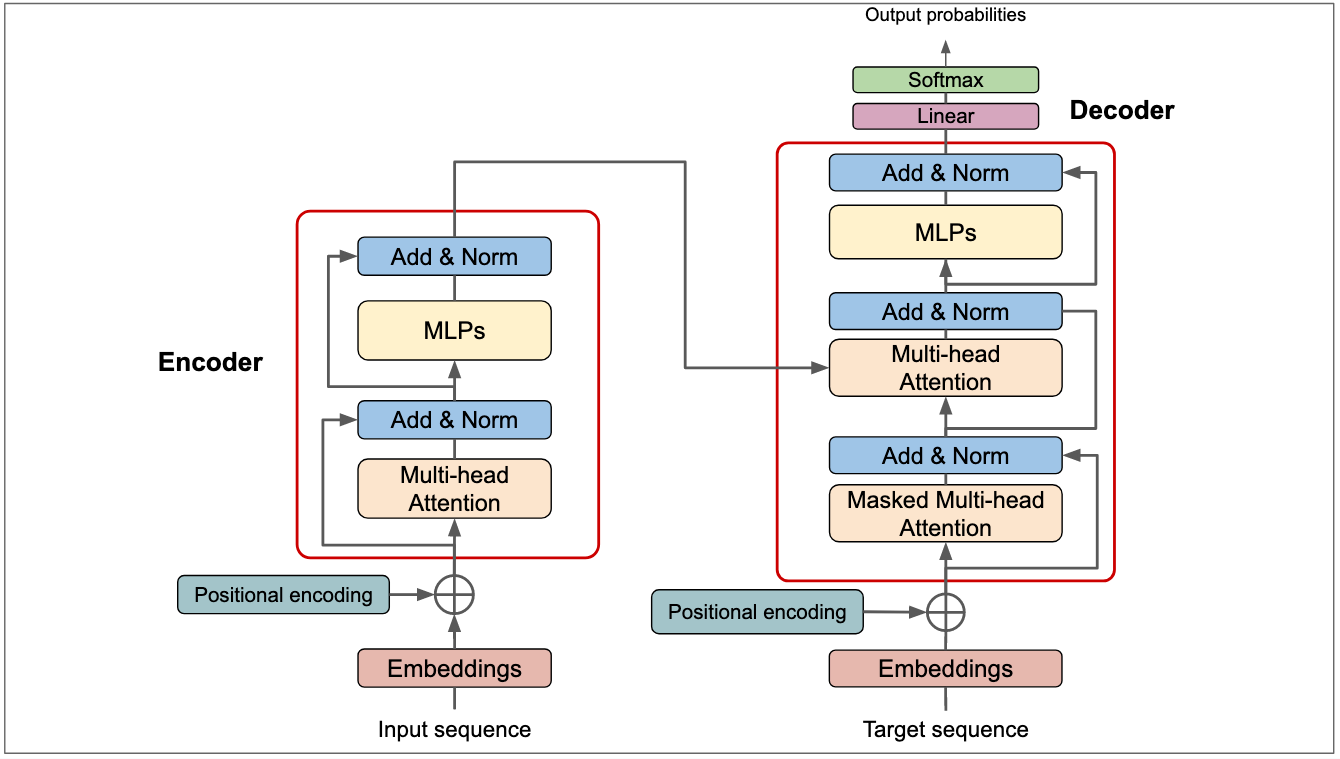
Large Language Models (LLMs) are an extension of the Transformer architecture, which was introduced in the paper “Attention Is All You Need (Vaswani et al., 2023) ” by Vaswani et al. in 2017. LLMs are designed to understand and generate human-like text by leveraging vast amounts of data and computational power.
The key difference between previous Transformer implementations ( translators, etc ), was the scale. LLMs are trained on massive datasets, often consisting of billions of words, and contain hundreds of millions to billions of parameters. This scale allows them to capture a wide range of linguistic patterns and nuances.
They have also broken a long standing precedent of specialized models for specific tasks, instead being able to perform well on a variety of tasks with minimal fine-tuning. This came as a particular surprise, as LLMs were found to be better at highly specific tasks than models that were trained specifically for those tasks(review categorization, etc).
A new field that has opened up as a result of LLMs is Mechanistic Interpretability, which focuses on understanding the internal workings of these models, often through techniques like circuit analysis, feature visualization, and probing.
Bibliography
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2023). Attention Is All You Need. arXiv preprint arXiv:1706.03762 [arXiv]