Markov chains are used for everything - statistics, biology, and machine learning of course. They allow for some very interesting probability theory.
Let’s start with an example.
Imagine there is a restaurant that serves 3 different kinds of foods: burger, pizza, and hot-dog. However, they have a weird rule where they only serve one of these 3 items on any given day. And, it depends on what they served yesterday.
Essentially, if you know the probabilities and what they served today, you could predict what they will serve tomorrow.
Let’s say we are given a graph with all 3 foods, with arrows pointing to other foods with a number between 0 and 1 for their probability.
If we are on pizza today, we can predict that there is a chance of having hotdogs tomorrow.
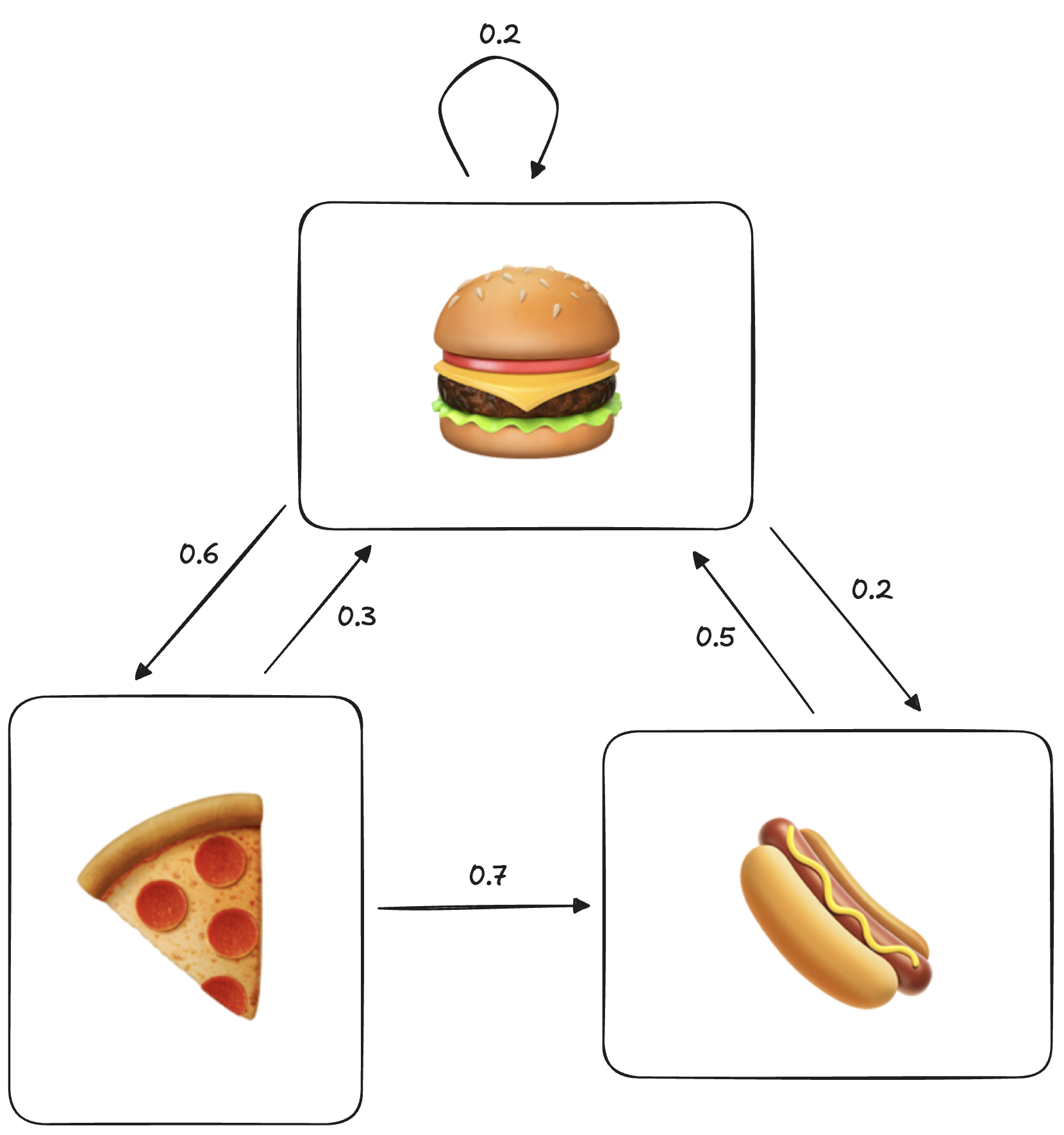
While quite a simple diagram, this is actually a complete Markov chain!
In more formal math notation, we can represent the probability of a certain food choice on a given day considering only what was had yesterday:
This is the essential property of Markov chains: you only need the previous state to figure out the next, and not the whole history/probability distribution.
Example
For finding the probability of getting Hotdog given that the previous day had Pizza(on the day):
This is known as the Markov Property.
The other important property is that sum of the weights of the outgoing arrows from any state is equal to 1. This makes sense, as 1 represents the total probability of an action, and if all options dont add up to it, something is wrong.
However, there are special Markov Chains with unique properties that break this rule, we will discuss later.
Exploring the Probability Distribution
To get a feel for what you might see over a long time period of this chain, lets walk the chain and see what we get:

After 10 steps, we are left with this. But how can we find the probability of each of the food items, aka a probability distribution? This is not a particularly meaningful question as it is quite simple, but leads to a bigger picture idea later.
Well, for each food we get the number of occurrences over the total sample size.
The more interesting question though, is what do these probabilities converge to? Aka, how does this new Markov graph translate to our more traditional probability summarization methods?
Let’s approach this with a brute force python implementation:
Running this, we find that the items converge to some interesting and quite specific values.
After this point, the distribution reaches a stationary state meaning it will no longer change with time. While this works, this is not a very efficient way to compute the distribution, and leaves the question if there is a more mathematical approach. We also dont know if there are any other stationary states.
Well, there is a better way to represent it, through the user of Linear Algebra
Using Matrices for Markov Representations
In reality, a Markov change is essentially just a directed graph, something we are very familiar with (as computer scientists for graph databases, and in theory of computing with Automota)
Because of this, we can represent the previous graph with a simple adjacency matrix:
Where the Columns represent the initial state, and the Rows represent the destination state.
In Linear Algebra, we would represent this as a Transition Matrix :
We will then use a secondary matrix to represent the probability distribution of the states. As the Markov Chain progresses through time, the matrix will approach values like the ones we found with the python Approach.
If we begin on a pizza day, the first state of the matrix would look like:
Something interesting happens when we multiply these two matrices together:
We have extracted the second row of the transition matrix, which happens to represent the probabilities of future foods given it is a pizza day.
Now, if you take this resulting value and put it in the place of the initial matrix:
We get this new interesting value. What does it mean? Let’s repeat this a few more time for the next few iterations of :
Notice how this seems to be getting closer and closer to the stationary state? Thats because it is!
If there exists a stationary state for this initial choice, then after repeating the process several times, the resultant matrix will converge on a stationary value. Eventually, the output vector will be identical to the input vector.
Denoting this special row vector as we can write(for a converging stationary state):
As Linear Algebra students, we will recognize this as similar to the eigenvector equation:
Just by considering and reversing the order of multiplication, we get our equilibrium state equation.
How do we interpret this? We imagine is a left eigenvector of matrix , with the eigenvalue equal to 1.
The eigenvector in this approach must also satisfy another condition: the elements of must add up to 1( as it is a probability distribution ).
After solving these two equation, we are left with the finalized stationary state:
Converting to decimal:
Very similar to our brute force approach!
Using this technique, we can also find out if there are more than one stationary state. This can be done, as you might expect, by finding out if there exists any more than one eigenvectors! Very nice.