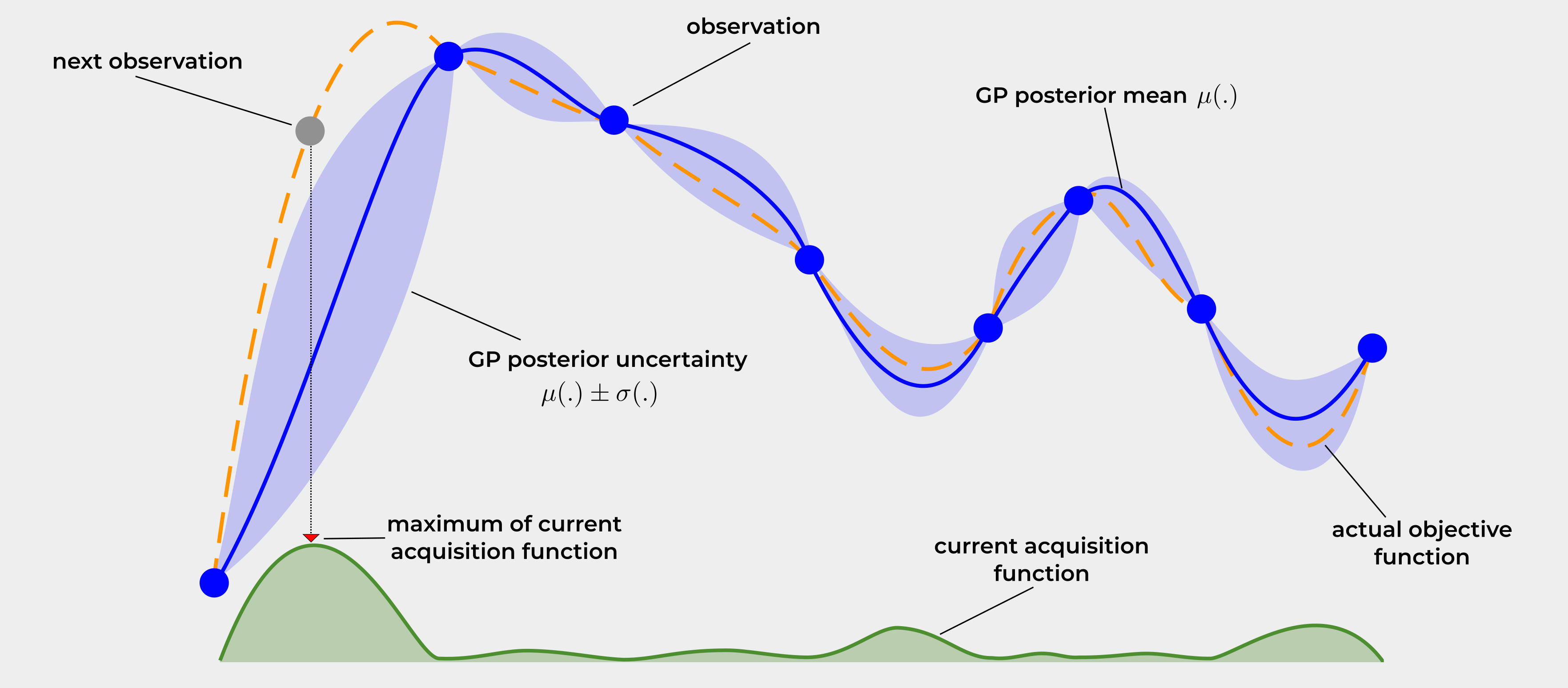
Approximation of a function with limited samples, where black box functions are expensive to evalauate. Essentially, trying to find the region of likelyhood for which the true function could reside, where the sampled points are seen as truth and the in between has a variable region of uncertainty. by quantifying the uncertainty we can make choices for where to sample next to “get the most bang for your buck”. exploration vs exploitation
Good for Machine Learning hyperparameters, use a probablistic model like a Gaussian Processes.
- Extended kalman filters and population kalman filters are integration free bayesian optimization methods
- tied to Gaussian Processes in modeler and optimizer. Gaussian Processes act as probablistic surrogate model within Bayesian optimization to model black box functions
- bayesian optimization seeks to optimize a function that is expensive to evaluate, whereas a gaussian process acts as this surrogate model
- GP is a subset of BO, all bayesian optimization methods need a surrogate model provider.
Quite an interesting little system, it is something I do need to do. Maybe also integrate with note on Kalman Filter, as that seems vaguely related.
Main Components
Surrogate Model: probablistic usually a GP, represents objective function and provides predicted mean and uncertainty, Confidence Intervals for unknown points.
Acquisition function: strategy, such as Expected Improvement determines next point most useful to sample, balancing exploration with exploitation.
Updating: after point evalutated, gets added to historical data, GP updated to better model the function with reduced uncertainty.