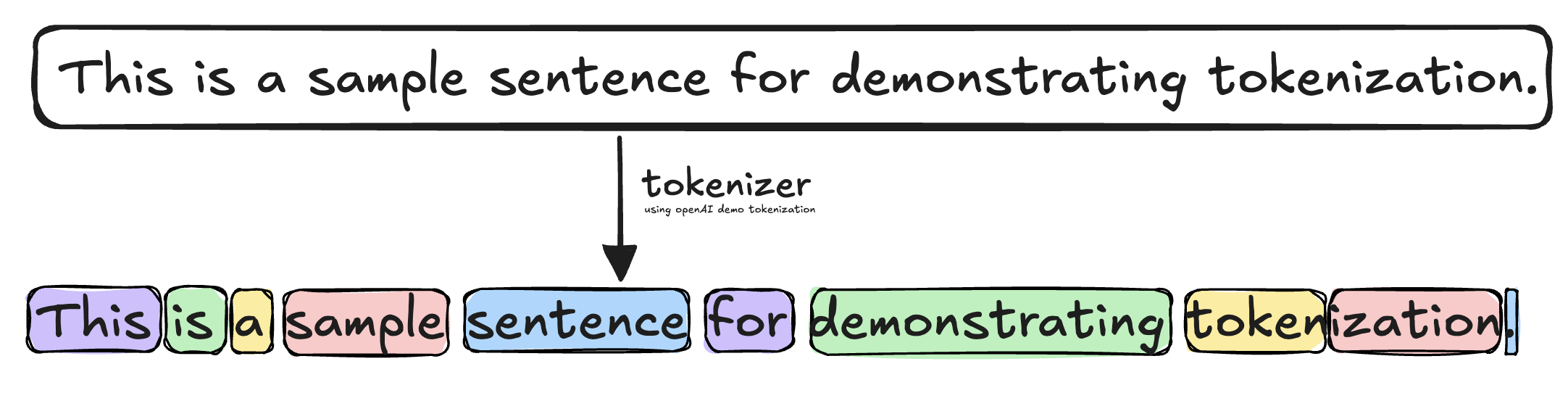
A token is simply an internal representation for Natural Language Processing models, where words are broken up into meaninfull fragments.
This has been found to improve accuracy over simply just embedding the word, as some combinations encode general meaning regardless of the word ( example: tokenization, the “ization” has meaning across words. )