As we discussed last lecture on Linear and Nonlinear Regression, for the case of linear regression we can solve the parameters with a closed form solution. But, to introduce the concept of Gradient Descent, we must build an intuition of the process.
Approach
We start by initializing parameters, usually either zeros or just randomly set.
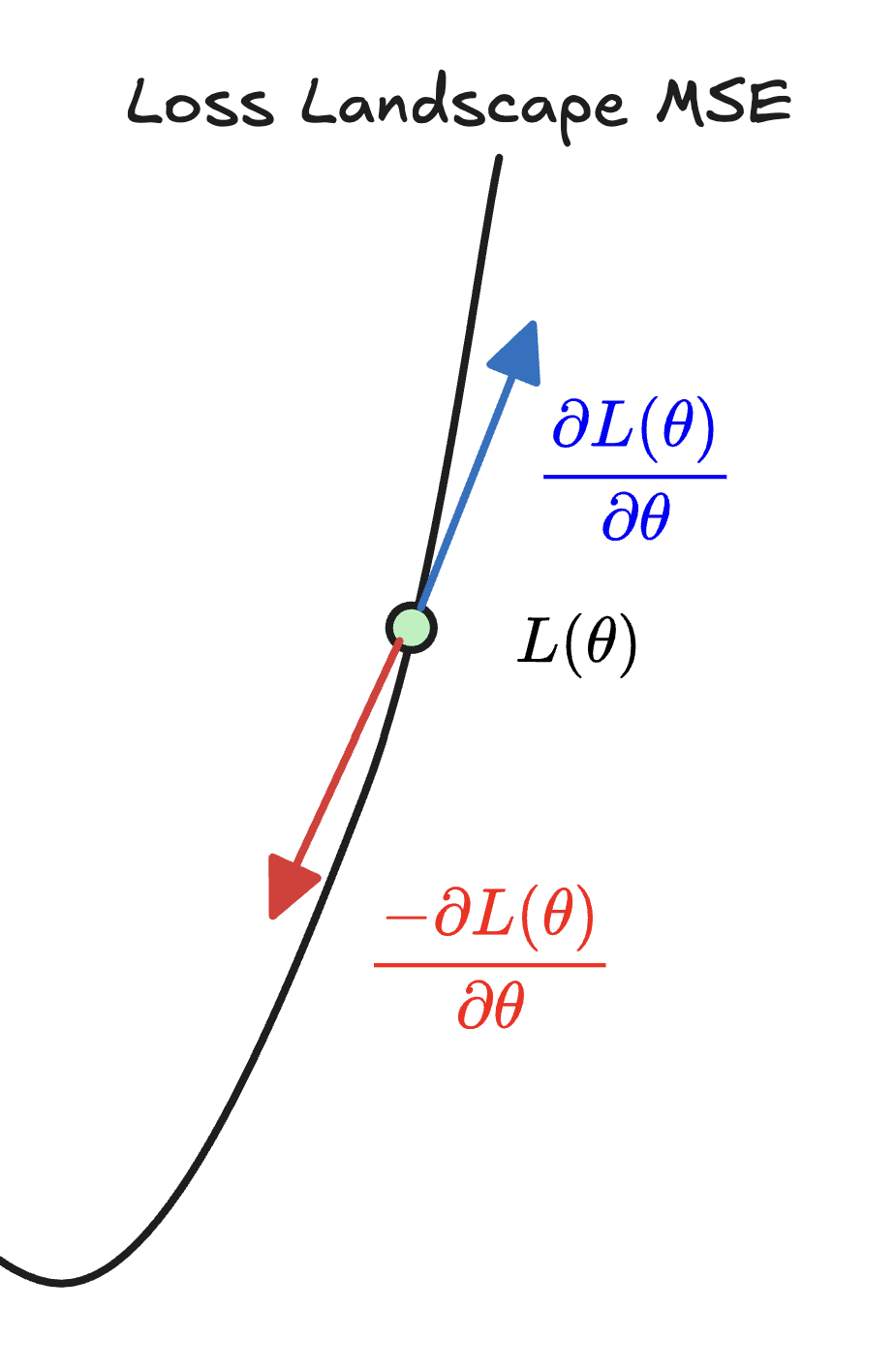
Then given the gradient of our Loss Function, we are looking to find the direction of fastest descent. Then we update our parameters in that direction scaled by a learning rate . This all comes together in the partial derivative of the loss function with respect to each parameter . If not familiar, I recommend reviewing Partial Derivatives, Vector Fields, and maybe 14.6 - Directional Derivatives.
We repeat until convergence . This is called Batch Gradient Descent since we are using the entire dataset to compute the gradient at each step.
Gradient Descent Variations
A few ones to be aware of:
- Batch Gradient Descent: As described above, uses the entire dataset to compute the gradient at each step. This can be computationally expensive for large datasets.
- Stochastic Gradient Descent (SGD): Instead of using the entire dataset, SGD updates the parameters using only one training example at a time. This can lead to faster convergence but introduces more noise in the updates.
- Mini-Batch Gradient Descent: A compromise between batch and stochastic gradient descent
To help mini-bath GF and SGF to reach the topimal solution, gradually reduce the learning rate by factor of 0.9 every epoch.
Feature Scaling
If features are different in sizes/scales. For example, one feature is in the range of 1-10 while another is in the range of 1-1000. This can cause the gradient descent to converge slowly or even diverge.
First approach is Normalization, where you rescale the features to a standard range, typically [0, 1]. This can be done using the formula:
There are several kinds of normalization, this is called Min-Max Normalization. There is also mean normalization, where you subtract the mean and divide by the range.
Non Linear Regression
What if your data is more complex than a straight line?
Can we use a linera model to fit it? Yah, but wont fit well.
How can we fix? We can add powers of features to create a polynomial regression model.
Polynomial regression can fit just about any curve, but be careful of overfitting. Use cross validation to select the right degree of polynomial.
This is what is used in Taylor Series approximations, but this time for regression. Polynomials in this case will look something like:
Regularization
Regularization is a technique used to prevent overfitting in machine learning models by adding a penalty term to the loss function. This penalty discourages the model from fitting the noise in the training data, leading to better generalization on unseen data.
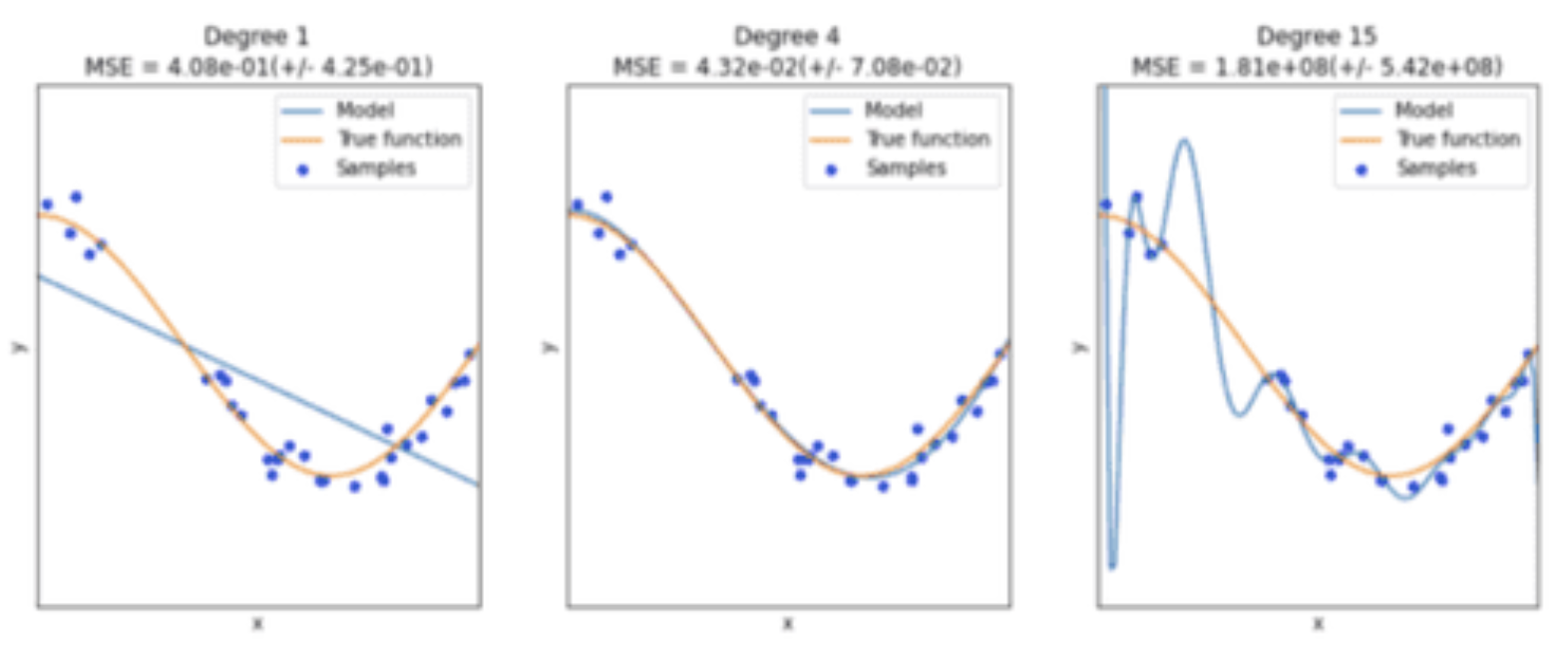
Noise is proprtional to model complexity. The more complex the model, the more it can fit noise.
Ridge Regression
Taking the our previous loss function for linear regression, we can add a regularization term to penalize large weights. This helps to prevent overfitting by discouraging complex models.
Adding regularization term:
Simplifying:
Where:
- is the feature weight
- controls how much you want to regularize the model. we call it Regularization Rate. It is multiplied by 1/2 for mathematical convenience when taking derivatives.
- means no regularization
In gradient descent, the cost function changes to:
Yielding:
Lasso Regression
Lasso regression is another regularization technique that adds a penalty term to the loss function, but instead of using the square of the weights, it uses the absolute value of the weights. This can lead to sparse models where some weights are exactly zero, effectively performing feature selection.
Elastic Net
Elastic Net combines both Ridge and Lasso regression by adding both penalty terms to the loss function. This can provide a balance between the two methods and can be particularly useful when dealing with correlated features.
When to Use What?
It is almost always prefereable to have at least a little bit of regularization to prevent overfitting, especially with complex models.
Elastic net is a middle ground betwen ridge regression and Lasso Regression. Use ridge when all features are relevant, Lasso when you want feature selection, and elastic net when you want a balance of both.
Maybe start wtih elastic net and tune the hyperparameters and using cross-validation to find the best balance for your specific problem. Then try ridge and Lasso to see if they perform better.