NEAT: method for evolving both weights and topology of neural networks. The main insight is that naive crossover of variable-topology networks breaks badly, and NEAT is specifically engineered to fix this.
Competing Conventions Problem
Before NEAT, the fundamental issue with evolving neural networks was crossover. Two networks can encode the same function with different internal structures — say, the same hidden neurons labeled in different orders. When you cross these, the offspring inherit mismatched parts from each parent and lose information.
This is the competing conventions problem: no matter how to cross two networks that use different structural conventions, the children will be worse than either parent.
NEAT solves this by giving every structural innovation a global ID — the innovation number — so genomes can always be aligned correctly.
Genetic Encoding
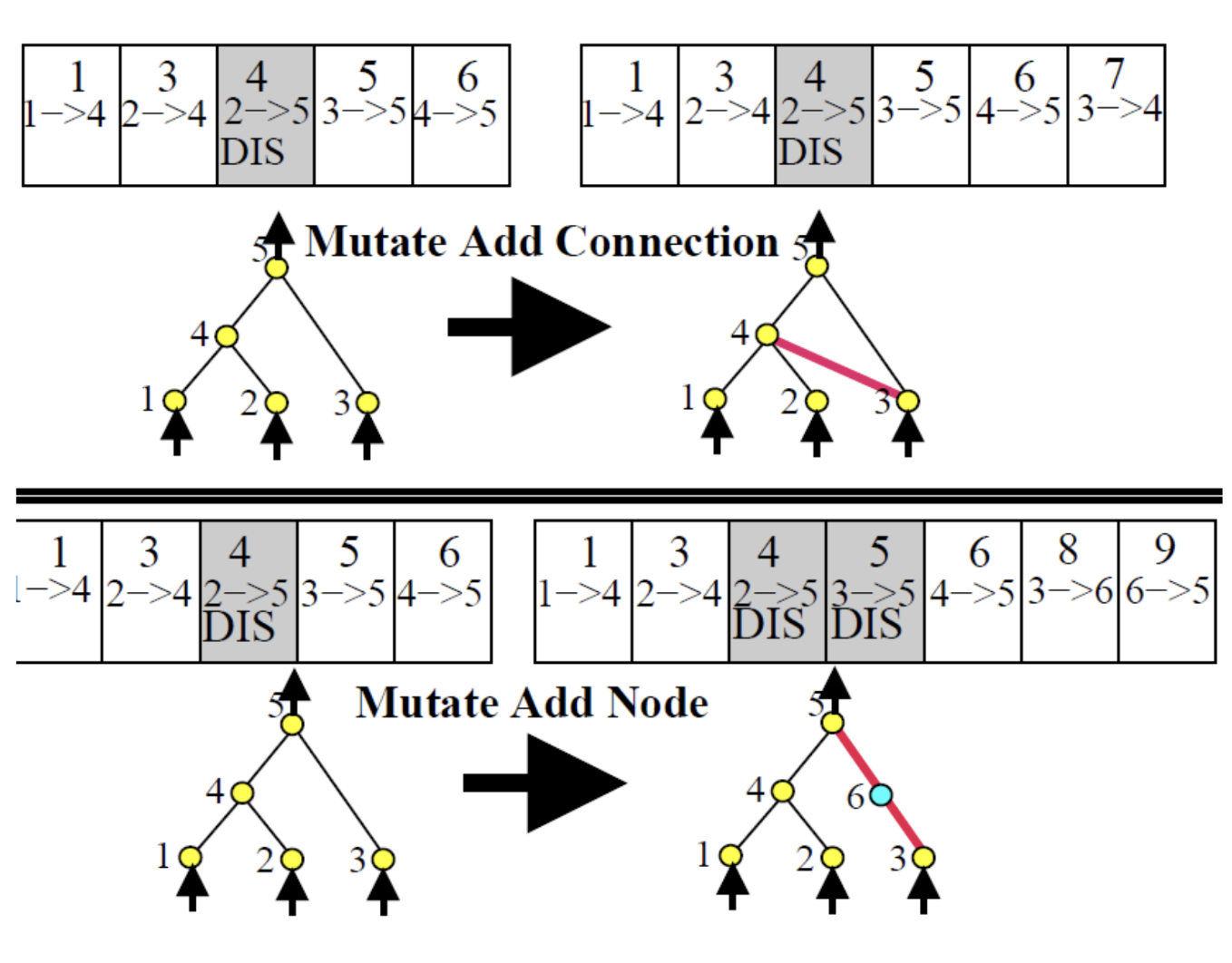
A NEAT genome has two gene types:
Node genes: simply list the nodes, each tagged as sensor (input), hidden, or output.
Connection genes: each encodes a single synapse:
In/Out(pre- and post-synaptic node IDs)WeightEnabled/DisabledflagInnovation number
The enabled/disabled flag is important: a gene can be disabled (silenced) but still remain in the genome and get passed to offspring. This preserves structural history even when a connection is functionally inactive.
Historical Markings / Innovation Numbers
The innovation number is a global counter. Every time new node or synapse appears in population( regardless of which individual it appeared in ), it gets assigned the current counter value, which then increments.
Result
any two genomes that contain the same structural innovation will have the same innovation number for it. This lets crossover align genomes by innovation number rather than by arbitrary position.
Innovation numbers make the genotype sortable. Alignment by innovation number is what makes crossover meaningful.
take parent 1, pull synapse 1, place it first; then go to parent 2 and check whether it has a synapse with innovation number 1. it does, it has a copy too. the fact that both parents carry a gene with the same historical marker means they share a common ancestor: that’s the point of the numbering scheme.
Mutations
NEAT has two structural mutations beyond standard weight perturbation:
Add connection: a new synapse is drawn between two previously unconnected nodes. Gets a new innovation number.
Add node: an existing synapse is split. The old connection is disabled, and two new connections are added — one from the original source to the new node (weight 1), one from the new node to the original target (inheriting the old weight). The old connection gene stays in the genome, just disabled.
Crossover
we can define the action of a crossver given two parent genomes, aligning all connection genes by innovation number. Then:
- Matching genes (same innovation number in both parents): randomly inherit one copy from either parent
- Disjoint genes (in the middle of one genome but absent in the other): inherited from the more fit parent
- Excess genes (beyond the range of the shorter genome): also from the more fit parent
offspring topology is determined by which genes get inherited. Because alignment is done by innovation number, the child always assembles into a coherent network — there’s no ambiguity about what connects to what.
HyperNEAT
HyperNEAT extends NEAT by using evolved networks not as controllers directly, but as weight generators for a separate substrate network.
The idea: use NEAT to evolve a CPPN (Compositional Pattern-Producing Network) — a network that takes spatial coordinates as input and produces a value. CPPNs naturally express regular, symmetric, periodic patterns because their activation functions (Gaussian, sine, etc.) compose cleanly.
You then “paint” this CPPN over the substrate: for each synapse in the controller network (defined by the 3D positions of its pre- and post-synaptic neurons), query the CPPN with those coordinates to get the synaptic weight.
HyperNEAT evolves the pattern of weights, not the weights themselves. The CPPN is a geometric prior.
The substrate network topology is fixed in advance; each neuron and synapse must have an explicit spatial location. The CPPN’s output dimensionality is determined by how many spatial coordinates you feed it — hence “hyper” cube.
HyperNEAT Vs FT-NEAT (Clune Et Al. 2009)
Clune et al. compared HyperNEAT against FT-NEAT (Fixed Topology NEAT) on quadruped locomotion. FT-NEAT uses the same substrate network as HyperNEAT and allows weight mutation and crossover, but no structural changes — it’s a direct weight-evolution baseline.
Results:
- HyperNEAT reaches roughly 2x the distance of FT-NEAT after 1000 generations
- HyperNEAT consistently finds regular, coordinated gaits across runs; FT-NEAT does not — its gaits are irregular and inconsistent run-to-run
Why? The CPPN encodes spatial regularities. A quadruped’s legs are geometrically symmetric, and the CPPN’s composition of periodic functions naturally discovers solutions that respect that symmetry. FT-NEAT treats each weight independently and has no inductive bias toward regular patterns.
Fitness Variance
For mutations, HyperNEAT produces a wider fitness distribution than FT-NEAT: more highly fit children, but also more catastrophically unfit ones. The bad children get discarded, so the effective gain is asymmetric. This is the signature of an encoding with higher evolvability — a single mutation can produce large, coherent changes.
For crossover, HyperNEAT offspring tend to stay closer to parental fitness than FT-NEAT. Because the CPPN encodes patterns geometrically, mixing two parent CPPNs still produces a meaningful pattern rather than random weight noise.