discussing how to properly conduct data science research, starting with a review of a paper highlighted in the source property
Reading Paper
Paper discussed is Rapid Onset of Gender Dysphoria in Adolescents and Young Adults a Descriptive Study, where a study on a group of parents of children with gender dysphoria was questioned.
Initial Thoughts
I took particular notice of the methods section, with one particular line:
Website moderators and potential participants were encouraged to share the recruitment information and link to the survey with any individ- uals or communities that they thought might include eligible participants to expand the reach of the project through snowball sampling techniques.
I drew an analog to something learned in Psychology class today, on the subject of sampling techniques. Notably, there is an area of concern regarding bias with this sampling technique, in that if the survey is being shared by word of mouth, parents who feel a certain way (and who know other parents who feel the same way) are more likely to share this survey with like-minded parents. Using this “snowball” technique as described in the paper is a little questionable.
Discussion
There is nothing really wrong with the data analysis of the paper itself, the issue is primarily with how the data is gathered. In addition to the snowball sampling technique, it should also be noted where the surveys were placed on the internet. Namely, the survey was only posted on forums noted as “trans critical”.
Data Science Lifecycle
How can we make sure we remain ethical in our studies?
Asking Questions
Use the mesoscale reflection:
- Which individuals does this implicate?
- what groups does this implicate?
- how does this implicate society?
Listen before you speak
- consult with implicated members of the gropus above about your question
- reflect on your biases - talk to different people about your project and get feedback - their “gut check” might be very different than yours
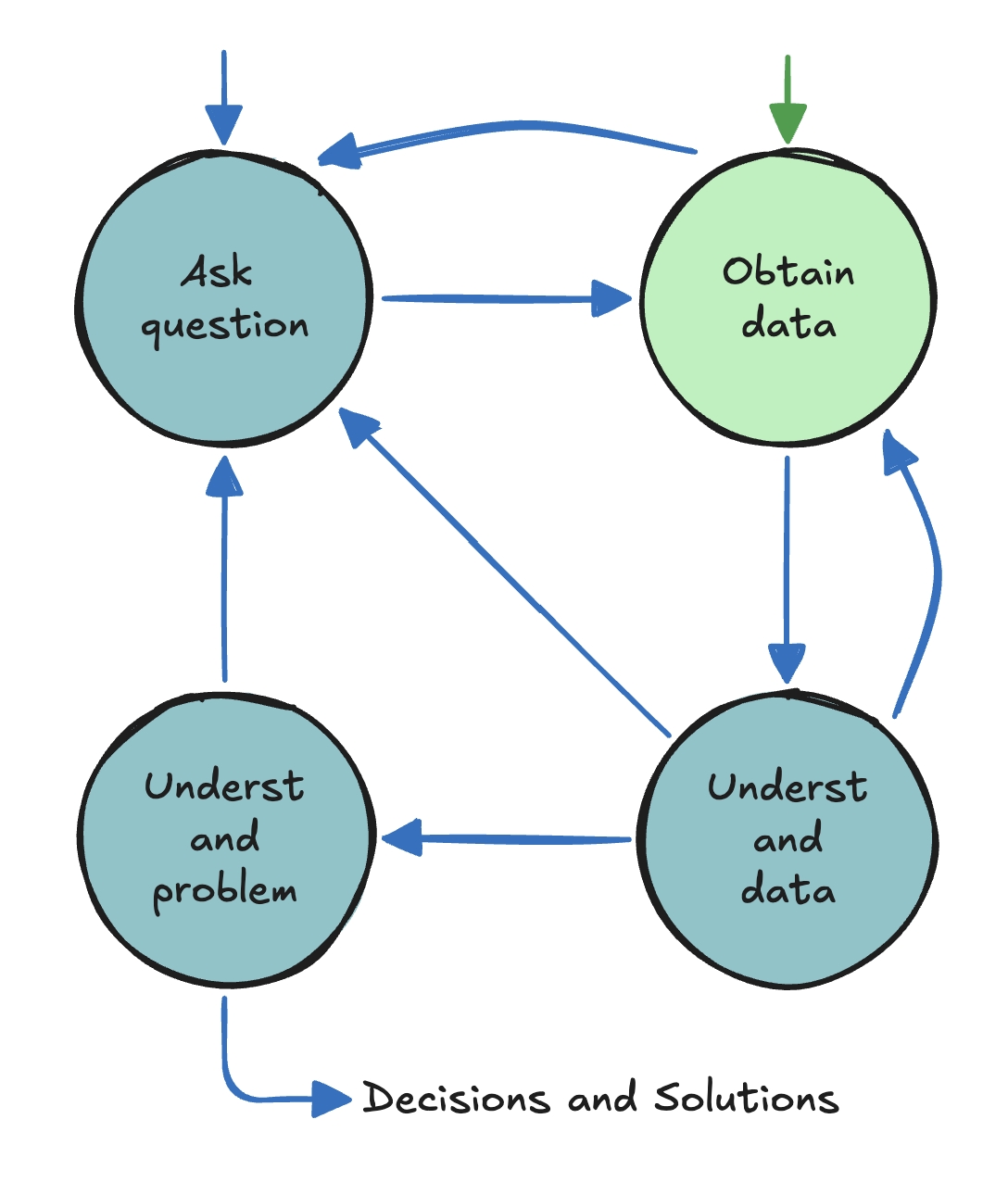
Obtain Data - Secondary Data
- Is this data balanced and representative
- Who are the data collectors, how was this collected, and in what context? - what are their biases?
- What metadata is available? If none, reach out talk to them
- Did the collectors get informed consent?
- Did the collectors have an IRB?
- etc…
There is also a question of data stewardship - a data management plan. One should follow by the FAIR + CARE plan principles, although the usefulness of a such a system has been mitigated by the introduction of generative AI.

Dark Data
One must also consider what data is not being collected - always assume you are seeing a subset of the full picture, and where the other side might be.
- What am I missing?
- Where is the rest?
This whole process should be guided by the principle of proactively looking for holes and biases in your data. Reflect on your feature engineering and possible introductions of biases.