Sparse Autoencoders are a technique for investigating Mechanistic Interpretability and the idea of Superposition and Polysemanticity.
The key idea is to use a separate learning algorithm to extract model features that often align with human-understandable concepts. Researchers can then amplify or suppress these features to observe their effect on the model’s behavior.
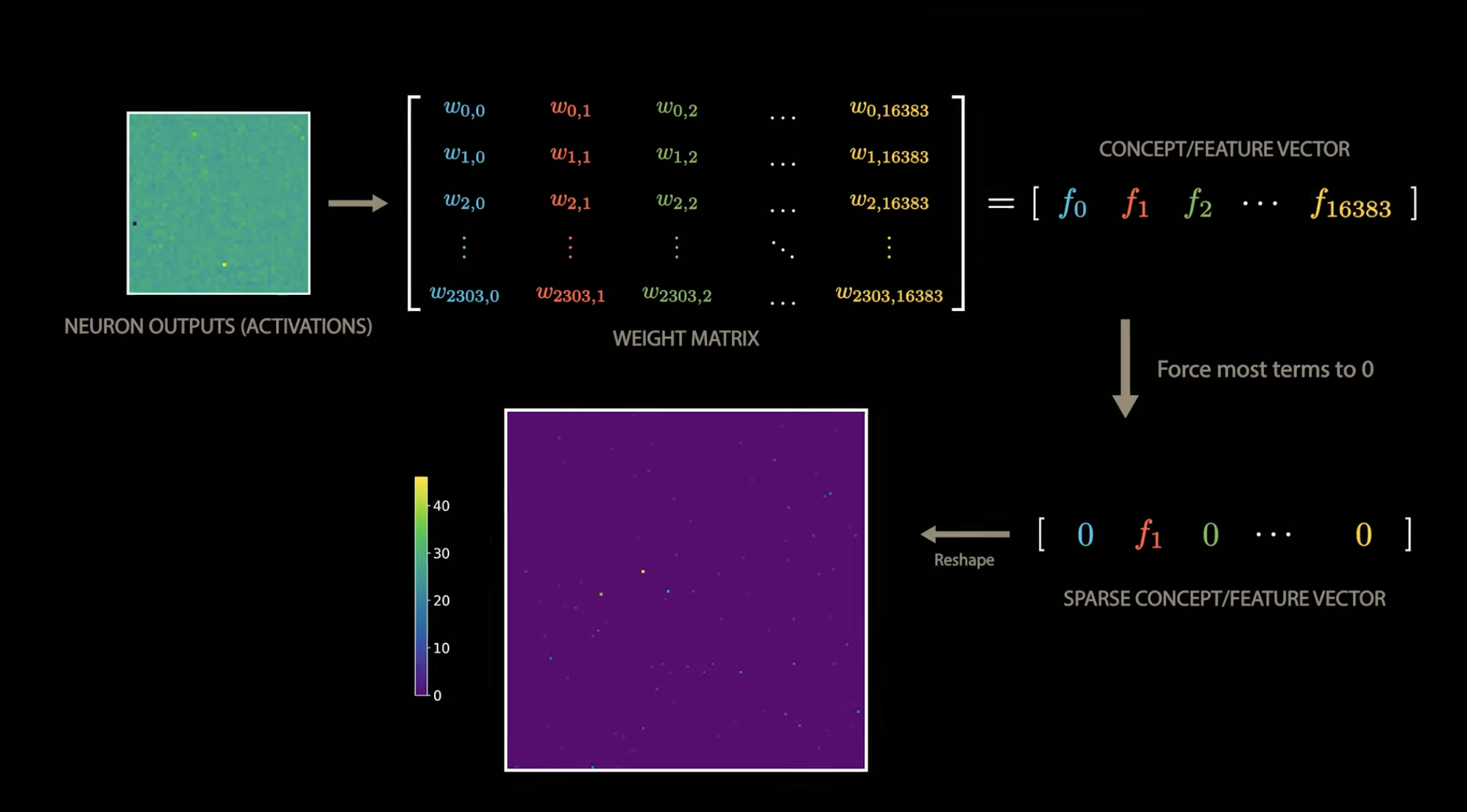
The primary operation is to train a sparse autoencoder on the activations of a specific layer in a neural network. The autoencoder learns to reconstruct the original activations while enforcing sparsity, meaning that only a small number of neurons are active at any given time. This encourages the autoencoder to learn more interpretable features.
This can be done by taking a matrix of activations from a specific layer in the model, where each row corresponds to a different input example, and each column corresponds to a different neuron in that layer. The sparse autoencoder then learns a weight matrix such that:
The loss function for training the sparse autoencoder typically includes a reconstruction loss term and a sparsity penalty term, such as: