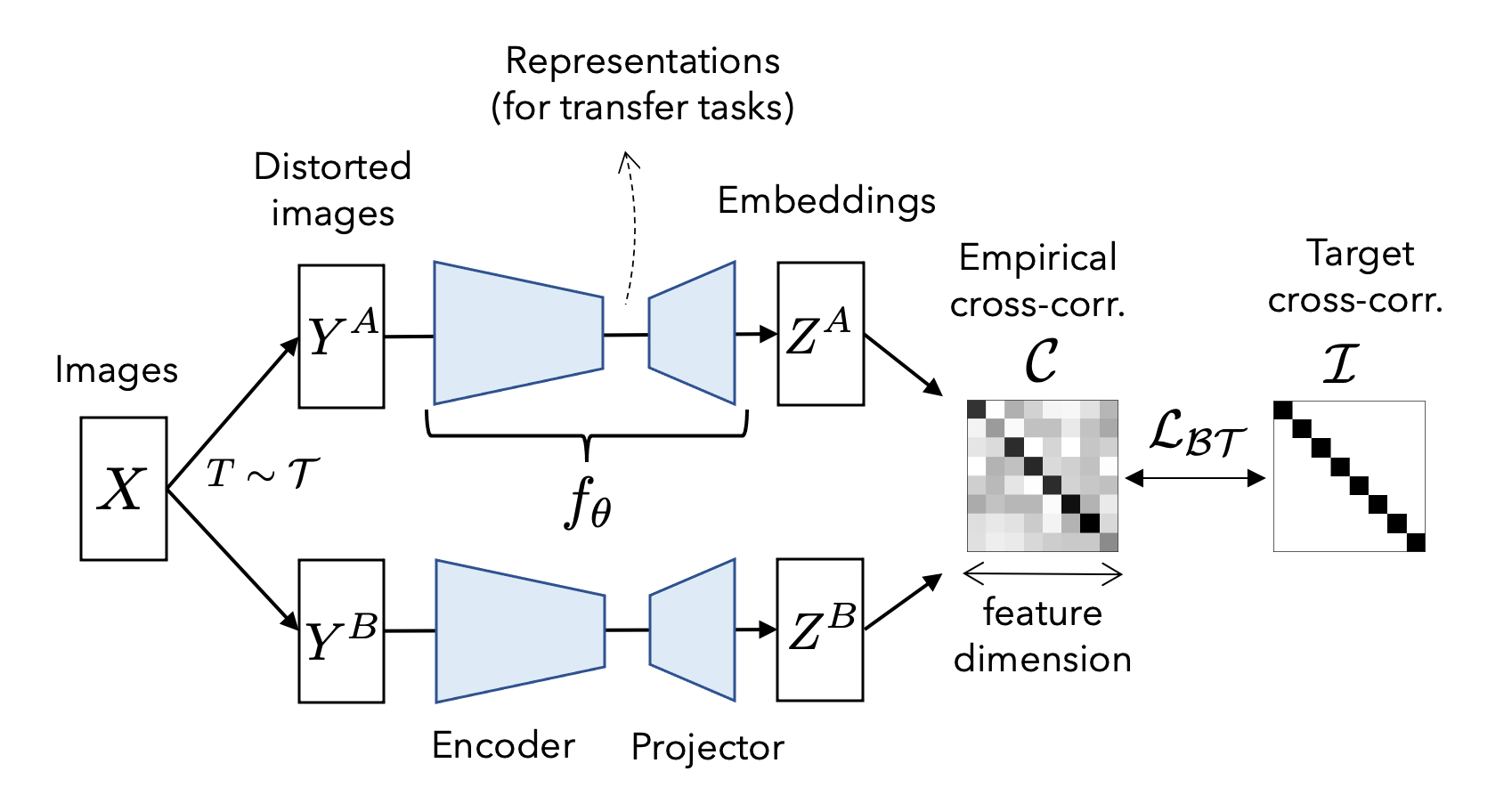
Self Supervised Learning method where objective is redundancy reduction.
- precursor to Joint Embedding Predictive Architecture in quite a few ways
- forces model to learn meaningful compressed latent space
Goes something along the lines of:
- twin inputs, where a batch of images is passed through a few random destructive augmentations ( remove a corner, shift colors ), creates two distorted views of the same data
- processed by two identical networks, usually something like a ResNet 50 encoder along with a MLP projector, to produce embedding vectors.
- cross correlation matrix computed between the two embeddings
- loss function consists of an invariance term, forcing the diagonal of the matrix to be 1 and ensuring network always invariant to image distortions, and also a redundancy reduction term to push the off-diagonal elements closer to 0, decorrelates different components of representation vector.